中国科学家牵头绘制精细水稻基因图谱,恢复“中国味”命名
作为“绿色超级稻项目”的一部分,“全球3000份水稻核心种质资源重测序计划”(3K–RG)于2011年9月由中国农业科学院、国际水稻研究所(IRRI) 和华大基因共同启动。2014年5月,3000份水稻基因组测序初始数据于“世界饥饿日”公开发布于NCBI、DDBJ、GigaScience、阿里云等数据库,于全球共享。
日前,3K-RG再获新进展。北京时间4月26日凌晨,国际顶级期刊《自然》(Nature)在线发表了绿色超级稻项目首席科学家、中国农业科学院作物科学研究所黎志康博士等人完成的最新成果,剖析了水稻核心种质的基因组遗传多样性,对水稻的起源、基因、分类和进化规律进行了深入的探讨。
所谓的“绿色超级稻”,其理念在上世纪末开始推出,旨在“少打农药、少施化肥、节水抗旱、优质高产”,以适应资源、环境的急剧变化。而上世纪60年代以来,中国水稻育种已实现两次重要突破,通过提高产量解决了温饱问题。
值得一提的是,研究团队此番在国际长期认可日本学者命名的情况下,对亚洲栽培水稻中“籼”、“粳”两大亚种恢复了具有“中国味”的籼 (Oryza sativasubsp. xian)、粳(Oryza sativasubsp. geng)亚种的正确命名。
该研究由中国农业科学院作物科学研究所牵头。中国农业科学院作物科学研究所黎志康研究员、国际水稻研究所Kenneth L. McNally和Nickolai Alexandrov高级科学家、上海交通大学生命科学与生物技术学院韦朝春教授、华大基因张耕耘博士、中国农业科学院深圳农业基因组研究所阮珏研究员、亚利桑那大学Rod A. Wing教授为该篇论文的共同通讯作者。并列第一作者则有中国农业科学院作物科学研究所王文生副研究员、国际水稻研究所Ramil Mauleon博士,上海交通大学博士生胡智强等12人。
论文的通讯作者之一、上海交通大学生命科学技术学院韦朝春教授对澎湃新闻(www.thepaper.cn)表示,“我们这个项目最大的好处在于,以前育种专家是靠经验、靠大量组合去试新品种,现在我们把3010份品种的基因组测完之后,相当于给育种专家提供了‘地图’。”韦朝春举例,比如需要的目标品种在生长早期要能耐淹、晚期要耐旱,那育种专家可以通过泛基因组数据库把具有这些性状的亲本去找出来,再进行杂交育种,“相比以前成功率会高很多。”
“日本晴”不再是最佳参考基因组
亚洲栽培稻是世界上最古老的农作物物种之一,生长于全世界,全球一半人口的主食依赖于它。此前有预计,到2035年需要额外增加1.12亿吨粮食才能满足未来人口增加的需求,但同时种植面积、水资源将更少,气候条件波动也更剧烈。
这就意味着,摆在育种专家面前的挑战是,未来的水稻栽培品种要更高产、抗压能力更强。
而水稻育种改良的遗传基础是水稻种群基因丰富的多样性和复杂的作用机制。长期以来,全球的科学家一直致力于阐明水稻基因组所有基因的功能及其等位基因多样性与重要农艺性状之间的关联,并将研究成果运用到水稻遗传改良中。而以基因技术为核心的分子设计育种,让水稻育种周期更短、更有针对性,代表了水稻育种的发展方向。
论文中提到,目前全世界所有基因库中概有上百万个水稻品种。在这项研究中,国际水稻研究所提供了来源于89个国家的2500份水稻核心种质,加上来源中国的500余份代表性材料,最终经基因测序、质量控制评估后保留3010株水稻的基因数据。
这3010株水稻代表了全球水稻种质约95%多样性的核心种质。
研究团队共检测到2900万个高质量单核苷酸多态性(SNPs,在基因组水平上由单个核苷酸的变异所引起的DNA序列多态性),240万个小片段插入缺失(Indels)。首次揭示了亚洲栽培稻品种间中存在9万个微细(>100bp)结构变异(SVs,包括易位、缺失、倒位和重复)。
韦朝春着重提到,以往研究人员采用的Nipponbare RefSeq(粳稻品种“日本晴”测序参考基因组)实际上在操作过程中给育种专家带来不少困惑,有基因图谱“不全”之疑。
此番,研究团队利用3010株水稻基因构建了亚洲栽培稻的泛基因组,发现了1.2万个全长新基因和数千个不完整的新基因。韦朝春表示,“原来的参考基因组大概有373Mb,我们现在新增了268Mb。”
其中,研究团队在3010份材料中再次挑选出453份测序深度较高的,来分析其核心(core)基因家族和分散式(distributed)基因家族。最后得出,共包括12770个(62.1%)核心(core)基因家族和9050个(37.9%)分散式(distributed)基因家族。核心基因比较古老,大多数的新基因则表现更年轻和长度偏短。
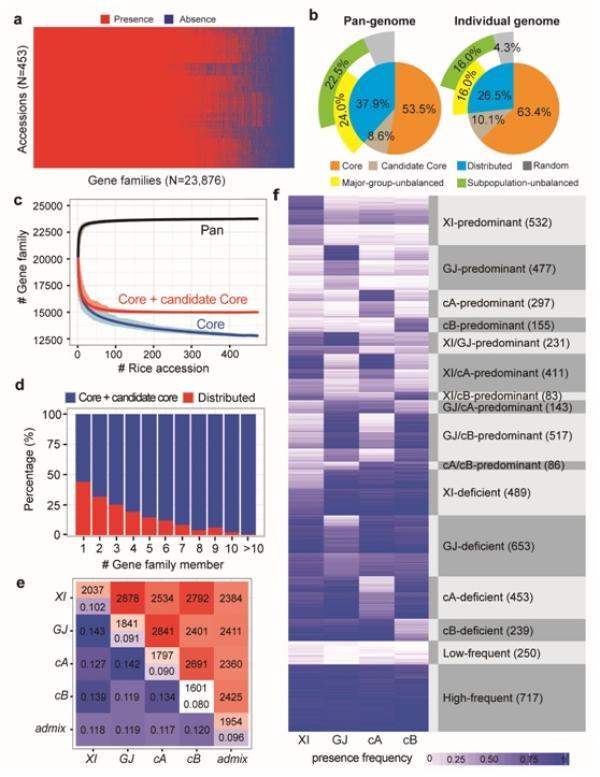
韦朝春提到,“以前大家可能认为核心基因很重要,而分散式基因不是必须的,但我们测试发现,大部分育种专家认为很重要的、和产量等相关的基因并不是核心基因,而是分布式的。”
这份信息更加丰富的基因数据库终极受益者是育种研究。据韦朝春介绍,在他们的泛基因数据库中,“你给我一个品种列表,我可以把这些品种共有的基因、特有基因都可以给你列出来,反过来你根据你的育种目的给我一个基因列表,我的泛基因组数据库可以告诉你有这些基因的品种有哪些。”这些工作只需要数秒钟时间就能完成,这在传统育种工作中是无法想象的。
此前传统育种主要是依靠水稻表型来作为选择依据,现阶段分子育种技术则是从基因组层面来确定目标性状,因其同时满足效率和安全(相对于转基因育种)的要求而备受科学界推崇。
值得一提的是,韦朝春还提到一个小细节。其团队在2013年加入该项研究,而这一项目的测序工作实际上早就结束,但海量的数据分析却面临技术瓶颈。“所有的测序初始数据有15T,在5年前的条件下,光这些数据从他们的机器拷下来再拷到我们的机器上,加上反复检查等因素,前前后后足足花了近半年时间。”
坚持恢复“中国味”命名方式
在水稻研究领域中,育种之外另一大关注焦点是其起源。
中国水稻研究的奠基人丁颖曾极力主张水稻原产中国。此番论文中也提到,亚洲栽培水稻中“籼”、“粳”两大亚种早在2000多年前的汉代已被人们所认知。丁颖也特意把籼稻定名为籼亚种,粳稻定名为粳亚种。
但籼/粳稻的起源和命名在国际上一直极具争议。
1928年,日本学者加藤茂范通过杂交等手段发现了籼稻和粳稻的区别。然而,加藤随后把籼稻称为“印度型” (Oryza sativaL. subsp. indicaKato),把日本栽培极广的粳稻称为“日本型” (Oryza sativaL. subsp. japonicaKato)。自此,籼稻和粳稻在国际上就一直沿用“indica”和“japonica”命名至今。
研究团队认为,这两个亚种用“印度”和“日本”来命名,很容易使人误解籼粳的亲缘关系、地理分布和起源。
研究团队在这项研究中对亚洲栽培稻群体的结构和分化进行了更为细致和准确的描述和划分,由传统的5个群体增加到9个。分别是东亚(中国)的籼稻、南亚的籼稻、东南亚的籼稻和现代籼稻品种等4个籼稻群体,东南亚的温带粳稻、热带粳稻、亚热带粳稻等3个粳稻群体、以及来自印度和孟加拉的Aus和香稻。
另外,通过对大量和驯化进化相关基因的单倍型和泛基因组分析发现,籼稻携带的很多基因不存在于粳稻中,粳稻的很多基因也不存在于籼稻中。此外,不同地理来源的水稻农家品种群体都带有特异的基因家族。
根据这些结果,研究团队首次提出了籼、粳亚种的独立多起源假说,并恢复使用籼 (Oryza sativasubsp. xian)、粳(Oryza sativasubsp. geng)亚种的正确命名。
据韦朝春透露,因为命名问题,《自然》编辑及文章审稿人曾多次和研究团队沟通,起初并不认可这种修正。“但黎志康老师坚持要把之前的误导性命名改过来,最终说服了对方。”
研究团队认为,正确命名使得中国源远流长的稻作文化得到正确认识和传承。
 奇!馆陶县公安局凭一份单方面制作的处罚书
奇!馆陶县公安局凭一份单方面制作的处罚书 “中国慈善榜”发布 上榜个人、企业合计捐
“中国慈善榜”发布 上榜个人、企业合计捐 特立尼达和多巴哥共和国总理将访华
特立尼达和多巴哥共和国总理将访华 集资入股诈骗近2千万元证据确凿,警员不作为
集资入股诈骗近2千万元证据确凿,警员不作为 中缅创新创业者“同台比拼”擦出“合作火花
中缅创新创业者“同台比拼”擦出“合作火花 专家谈如何保护民营企业家:以广东观音山国
专家谈如何保护民营企业家:以广东观音山国 中俄界江同江至下列宁斯阔耶春季气垫船运输
中俄界江同江至下列宁斯阔耶春季气垫船运输 中国“一箭五星”成功发射“珠海一号
中国“一箭五星”成功发射“珠海一号 “潜龙三号”试验性应用首潜归来 带
“潜龙三号”试验性应用首潜归来 带 中国各地盆景大师携精品上海竞艺 流
中国各地盆景大师携精品上海竞艺 流 千年古县东阿发展“绿色经济” 激发
千年古县东阿发展“绿色经济” 激发 平潭海峡公铁两用大桥完成首个航道主
平潭海峡公铁两用大桥完成首个航道主 10月新规来了!事关身份证、车子、电
10月新规来了!事关身份证、车子、电 北京一律所发文拒聘川大毕业生,第三
北京一律所发文拒聘川大毕业生,第三 代理商揭秘张庭公司套路:把代理商称
代理商揭秘张庭公司套路:把代理商称
